Why Relational Databases are not the Cure-All. Strength and Weaknesses.
Posted on May 14, 2015. Updated on Jan 20, 2019
Relational Databases seem to be the universal hammer in the toolbox of every developer. There is the notion that you can solve every problem with it – you just have to smash hard enough. However, if you use relational databases out of habit, you can easily run into troubles when it comes to schema evolution, scalability, performance or certain domains. This post discusses the strength and weaknesses of relational databases and points out alternatives.
Weaknesses of Relational Databases
Let’s start with a summary of the drawbacks of relational databases:
- Impedance mismatch between the object-oriented and the relational world.
- The relational data model doesn’t fit in with every domain.
- Difficult schema evolution due to an inflexible data model.
- Weak distributed availability due to poor horizontal scalability.
- Performance hit due to joins, ACID transactions and strict consistency constraints (especially in distributed environments).
Next we take a closer look at the mentioned points.
Impedance Mismatch
The application layer of an application is typically written in an object-oriented language. However, the object-oriented and the relational data model doesn’t fit well together. In the object-oriented world you have objects that are connected via references. They build an object hierarchy or graph. Contrarily, the relational model saves data in two-dimensional tables with rows for each entry and columns for the entry’s properties. If you want to store your object graph in a relational database, you have to slice and flatten your object graph until it fits into multiple normalized tables. This is complex and unnatural (following the OO notion). Moreover, if you want to recover the objects you have to join several tables, which can lead to complex queries and performance issues**.** Consider the following example:
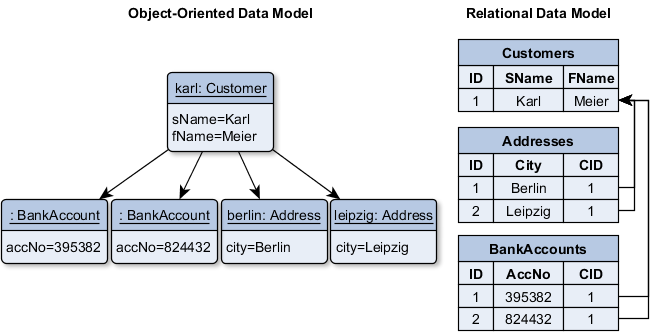
Comparing the object-oriented and the relational data model. These two worlds doesn’t fit together naturally.
The Customer Karl has references to two BankAccount objects and to two Address objects. In the schema, there are three tables for each class (Customers, Addresses, BankAccounts) and each table is filled with the corresponding data. Furthermore the entries for the addresses and the bank accounts have a foreign key pointing to the entry in the Customer table. It is remarkable that the direction of the relationship in the relational model is the reverse of the original one. That is why I call the relation model unnatural for the object-oriented developer. Moreover, the data distribution over several tables gets even more complicated when there are intermediate tables necessary (for n:m relationships).
Sure, there are Object-Relational-Mapper (ORM) like Hibernate out there, doing a good job of serving as an abstraction layer and making the whole mapping process transparent for the application developer. But Hibernates adds quite some complexity to your application (which can be a pain when it comes to debugging or tracking performance issues) and significantly restricts your flexibility in terms of class design and query expressiveness. For more details, see the post “Do-It-Yourself ORM as an Alternative to Hibernate”.
Unsuitable Data Model for Certain Domains
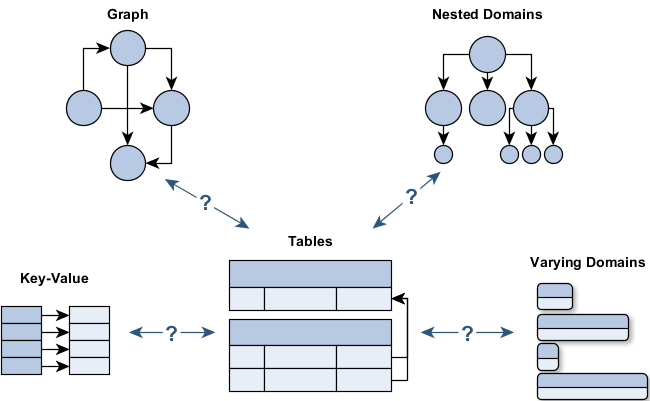
Some domain models can’t be mapped well (or efficiently) to the relational model
Your domain model is a highly cross-linked graph? Using a relational database to traverse the graph will easily become a nightmare because of the huge amount of necessary joins. Using a graph-based database (like Neo4j) would be much more appropriate.
The same is valid for deeply nested domain models (hierarchies) that would require a lot of tables and joins. Document-oriented databases (like MongoDB or CouchDB) are the best choice for these domains.
Sometimes the entities of your domain can vary in a wide range. Let’s say, you have the entity User with some base properties (name, E-Mail, state, address). However, a Customer can have a huge variety of additional optional properties (isCompany, company legal form, sales tax ID, isPartner, partner shop, isKeyAccount, discount etc). How would your relational schema look like? A huge table with all possible columns (setting the unsuitable properties for an entity to null)? What if you want to add new properties (see Schema Evolution)? Mapping the object-oriented concept of inheritance to the relational model is hard (see Impedence Mismatch). The problem is the fixed and restrictive schema. If your domain is highly variable, consider using a document-oriented database. These databases are schema-less and don’t restrict the structure of the inserted data.
Your domain consists primarily out of key-value-pairs? You need extremely fast access to simple data that is not interrelated (like a user’s session in a web shop) or a fast caching mechanism? Key-Value-oriented databases (like Riak or Redis) are much faster than any other database type.
As you can see, pressing all domain models into a relational database can get very uncomfortable, unnatural, slow or sometimes well-nigh impossible. If the database already supports the desired domain model no mapping is necessary, the domain modelling is not restricted by the persistence model and the development will be easier and more direct.
Difficult Schema Evolution due to Inflexible Data Model
Changing a schema can be tough.
When using relational databases you have to define the structure (tables, columns, column types, foreign key relationships, non-null constraints) of your data model up front. This fixed and strict structure provides safety, but is hard to change afterwards. For instance, it is laborious to add or remove a column in the production database, when there are already a lot of entries. Migration scripts are necessary. Besides, it is a mental obstacle. You do all you can do to implement a feature without changing the schema, because it’s so painful. This hinders the constant improvement of a schema and leads to misuse of the schema.
In addition, introducing Continuous Delivery is harder. Every change in the application can lead to schema changes. Hence, existing data has to be migrated. Using Continuous Delivery, you deliver frequently and so you have to update the schema and migrate the data frequently. This not a trivial task, although tools like Liquibase, Flyway or DbMaintain can help to automate the versioning and update of the schema. See “Databases as a Challenge for Continuous Delivery” for more details.
Weak Distributed Availability due to Poor Horizontal Scalability
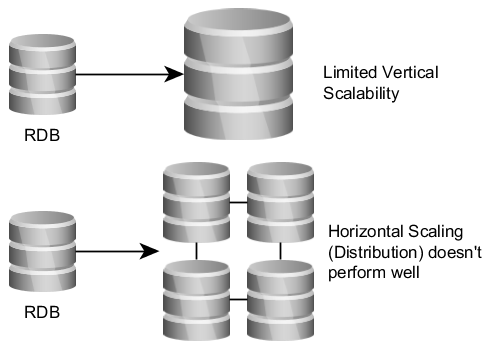
Relational Databases and Scaling Options
Do relational databases scale well? Well, they can scale vertically (using a better CPU or adding more RAM). But vertical scaling is limited by physics and the budget.
However, horizontal scaling (connect multiple machines to a cluster) doesn’t work well with relational databases. This is because of the strict consistency requirements. The mechanisms for enforcing consistency (e.g. locks and blocking approaches used for ACID transactions) are slowing down the performance if the database is distributed. For instance, each lock or primary key generation requires network communication and is affected by the network latency. This leads to long running transactions and an increased response time of the system.
All in all, the strict consistency constraints are doing well for ensuring consistency, but decrease the high-availability of the system in distributed scenarios. If high-availability is more important than strict consistency and eventual consistency is good enough for you, than relational database are not the best choice. For instance, for a customer of a web shop, it’s totally OK, if a recently added article is visible only some minutes after it has been created by the staff (it takes some time to spread the new data across all nodes). Short response times are more important.
Performance Hit
The drawback of decreased performance was already mentioned multiple times (see Impedence Mismatch and Weak Distributed Availability).
If your schema is normalized you have to use multiple joins to collect together the data you need. Joins are expensive. That’s why it makes sense to denormalize the schema in order to decrease the number of necessary joins and in turn improve the performance. However, this leads to redundancy and the danger of inconsistency, which must be handled at the application layer.
Besides, the mechanisms for ensuring consistency (locks used by transactions; rollback capability) and the constraint checks (column types, uniqueness, referential integrity) are an overhead you pay with every statement you send to the database.
An Alternative: The Document-oriented Database MongoDB
Document-oriented databases can solve some of the issues of relational databases. Document databases store data in objects
- that can be deeply nested and
- can consist of arbitrary fields.
A common representation of the objects is JSON. MongoDB is a very popular document database and we will take a closer look at it in the following section. The following example shows a possible JSON representation of our customer object in MongoDB.
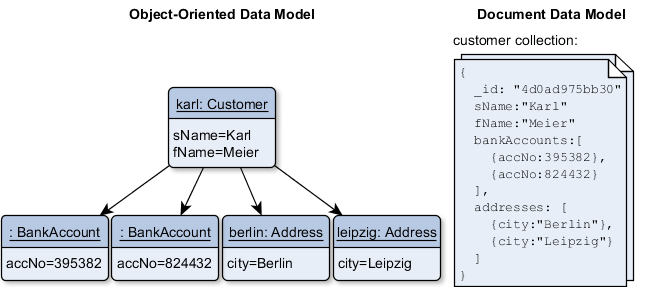
A document database stores data in nested objects, which perfectly match for the object-oriented model.
Schema Flexibility. You can pass an arbitrary JSON to the database. It will happily accept everything you submit. There are no schema restrictions like defined columns per entity or type checks. Customer object Karl can contain totally different fields than customer Paul. This flexibility enables an easy schema evolution, because there is no schema. Added or removing a field to existing entities is no problem. Schema flexibility is also useful when the entities of your domain are varying in a wide range or the structure of the data model is not known in advance or changes frequently. But “with great power comes great responsibility“. Document databases **exchange **safety for flexibility. A simple typo in a query (e.g. querying “name” instead of “sName”) wouldn’t cause an error. The database will happily process the query and return an empty result set and you will never know that you did something wrong. However, using a Object-Document-Mapper (like MongoJack) can solve this problem, because the developer doesn’t need to construct queries via string concatenation anymore.
Using a schema-free database can also help introducing Continuous Delivery. Data with old and new structure can exist in parallel in the database. Consequently, no schema update and data migration is necessary, when a new version of the application is deployed. However, your application has to handle the case that there are different structures for same data in the database. You may still want to migrate your data to the new structure, but you are not forced by a schema.
**Easy access to nested data. **MongoDB is a good match, if your data is nested. MongoDB provides a query capability that enables you to easily access nested properties. However, your data doesn’t need to be apparently nested-able to store them in MonogoDB. In cases you use joins in the relational database, you can often replace them with nesting. This is a more natural and object-oriented way of modelling anyway. Indeed document databases map very well to the object-oriented model. Ideally, all of your object’s data should be stored in a single document. So there are no joins necessary to recover the object from the document. Hence the object-document-mapping is very straightforward, fast and there is nearly no mismatch.
Typically a document should contain all data you need for normal use. You cannot join documents in MongoDB. That’s why denormalized data and plain reference IDs are the norm. This implies that you have to think about the way you plan to use your data in advance (e.g. avoiding the need for joins and storing all necessary data in one document). Otherwise you can easily find yourself in an inconvenient situation, where you cannot comfortably retrieve the data you need due to the document’s structure. This is a huge difference to the query flexibility of relational databases where you nearly always get the data you want (as long as your data is normalized). But the lack of joins, the denormalization and the coherent structure is intended because they enable high performance and easy replicating of data across several servers. This is therefore important for MongoDB’s scalability. In fact, the strength of MongoDB lies in the easy access to BIG data.
If MongoDB is scaled properly and the necessary data is stored within a single document, we can get rid of intermediate caching (like ehcache; hibernate’s second level cache) and attach our application directly to the database. This significantly reduces the complexity, possible errors and invalid states (just consider the topics cache invalidation and distributed cache). Besides, there is no mismatch anymore. So we don’t need a (sometimes complex, hard-to-debug and error-prone) ORM/Hibernate stack as an abstraction layer anymore.
Strength of Relational Databases
It would be unfair stating only the weaknesses of relational databases while hiding their strengths. Indeed relational databases have several advantages and are in many cases a very good choice. They can easily handle gigabytes of data. But the crucial question is: What are acceptable response times for your application? For instance a web shop requires much shorter response times than a backend system.
- Query flexibility. As long as your schema is normalized, you don’t have to know up front how you will query your data. You can always gather together the data you want using joins, views, filter and indexes.
- Consistency via ACID transactions. The relational database ensures that your commits are always atomic, consistent, isolated and durable. If an error occurrs, the whole transaction can be rolled back, restoring a consistent state. This is critical in some domains (e.g. banking). But note, that some NoSQL databases also provide transactions or at least some ACID properties (Couchbase, Neo4j, HBase). Besides transactions can also be coded into the application layer. If we think about transactions from a business point of view they have to be implemented in the application layer anyway, because they span more than just the act of saving data. However, keep in mind that long-running transactions are more likely to fail and can easily become a bottleneck.
- Safety due to defined schema and strict constraint checks (e.g. column types, uniqueness constraints, referential integrity). Your data has a fixed structure you can rely on. You cannot accidentally misspell a column name, submit a string instead of an integer or enter a non-existing foreign key. The relational database will refuse the query and tell you. This is very comfortable. However, data validation and constraint checking can also (and often must) be done in the application or user interface layer. Validating data only in the database is often too late. Usually the user’s input has to be checked at a upstream layer anyway. Moreover, complex business validation cannot be done by the database. Hence, it is questionable if a redundant check done by the database is really necessary (extra maintenance effort and performance hit).
- Maturity. 45+ years of industry experience leading to mature databases, tools, driver, programming libraries, ORM. Knowledge of RDBMS is a basic skill every software developer has.
- Huge toolkit (trigger, stored procedures, advanced indexes, views) available.
Final Recommendations
It is likely that your database will be the bottleneck of your application. Hence, you have to choose your database wisely. But when it comes to choosing a suitable database, there is no right or wrong. There is only an appropriate or inappropriate depending on the requirements. All good is never together. Here are some trade-offs (relational vs document-oriented database):
- Schema safety vs schema flexibility
- Query flexibility vs scalability (performance)
- Transactional consistency vs availability (performance)
To wrap up, here are some final recommendations. Use document-oriented databases when…
- … the final data model is not known in advance.
- … the requirements for the data model are changing frequently or are unclear at project startup. You can just start with a first approach and improve it during the project.
- … it is likely that you need to easily change the data after is has been rolled out in production.
- … you want to use Continuous Delivery.
- … you need to handle big data and therefore want to scale horizontally.
- … when high-availability is an important requirement.
- … when your domain requires a lot of nesting.
On the other side, relational databases are a good choice when…
- … you don’t know up front how you will later query your data and you need flexibility here.
- … transactional consistency is important for your domain. But coding (business) transactions into the application layer is also possible and sometimes necessary.
- … the data of your domain is pretty regular (i.e. a constant set of properties per entity). In this case it makes sense to enforce this regularity by a defined schema.
- … you need safety and error-detection when using the database (defined columns, types, uniqueness, referential integrity). But keep in mind, that data validation can also (and often must) be done in the application layer.
- … your data is not highly interrelated (i.e. only a few references between the entities spanning a graph).