Databases as a Challenge for Continuous Delivery
Posted on Nov 28, 2015. Updated on Jan 20, 2019
Applying Continuous Delivery means to automate the delivery pipeline and to release frequently. However, databases are a big challenge, because with every deployment we may need to update and migrate our database before we can deploy our application. This post points out solutions for dealing with databases in a Continuous Delivery scenario.
TL;DR
Let’s start with a summary of the most important points:
- Try to make the schema changes backwards compatible
- Separated data sources for each deployment unit
- Schema update and data migration
- Relational databases: Use a migration tool to track changes and to automatically update the database.
- NoSQL databases: No database update necessary as long as the application handles the varying data structure. Nevertheless, we may still want to migrate our data.
- Coordinated workflow for deployment and data migration during operation
- It’s easy without high availability constraints: Shutdown application, update database, deploy new application, restart application
- It’s hard when high availability is required: Multiple intermediate versions of the application and update application instances step by step
The Problem with Database Updates
Updating the database is much more demanding than updating our application. Why?
- We have to adapt existing data. This can be very difficult if there is a huge amount of data.
- It’s hard to roll back changes done in the database in case of a critical error. Sometimes it’s even impossible.
- Database changes are difficult to test, because we would need a database similar to the production database.
We have to face these problems no matter if we are applying Continuous Delivery or not. But in case of Continuous Delivery we want to deploy frequently. In turn, we have to deal with these challenges more often.
Backwards Compatible Schema Changes
A good strategy to achieve independently deployment of (micro)services is to keep the interface of the service backwards compatible. If we change the service interface we still maintain the old version of the interface for some time. This way, we can deploy the service and don’t need to change downstream services. We can apply this approach to databases and consider the schema as the interface of our database. We change the schema in a way that is still compatible with the old version of the schema. Sure, this won’t work in many cases, but in some.
Example 1: Let’s say we want to add a column in a table. How can we add the column while still staying backwards compatible with applications that doesn’t know the new column? If the application reads entries from the table, we simply ignore the new column. If the application writes a new entry, we can use default values for the new column. Indeed, it’s up to our use case if this approach is acceptable, but this way we can change our database independently from the applications.
Example 2: We want to remove a column from a table. First, we have to make the column optional. Now we can take some time to update the accessing applications so that they don’t write or read the column anymore. During this time our schema is backwards compatible. After we’ve updated all applications we can remove the column from the schema.
Separated Data Sources
As we had seen, shared access to a database makes database updates difficult, because we have to update all dependent applications. Besides, we have to update the database and all applications in production at the same time. This coordination can be very challenging. Being backwards compatible is only sometimes possible. Hence, it’s a good strategy to avoid shared access to a database.
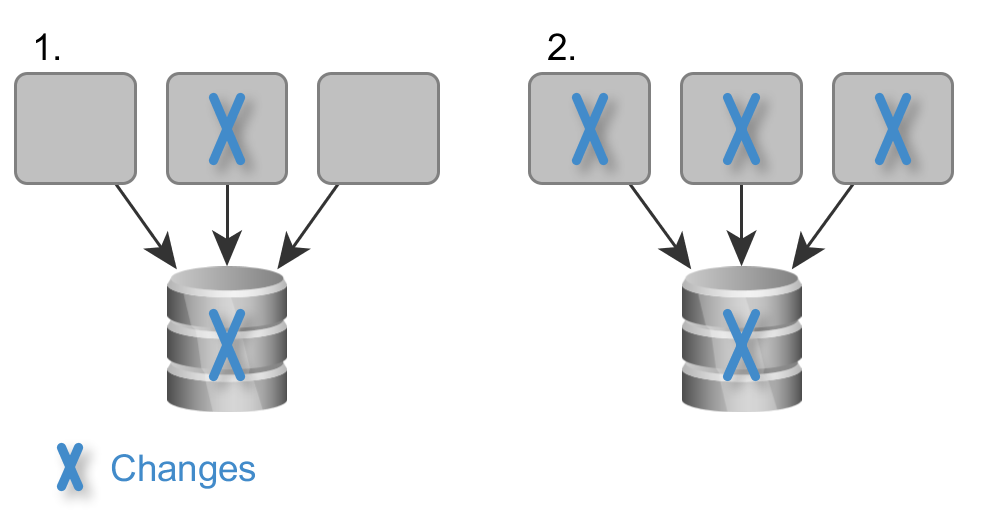
Shared Database: If we change the database, we have to update all accessing components and to coordinate the deployment of all components and the database.
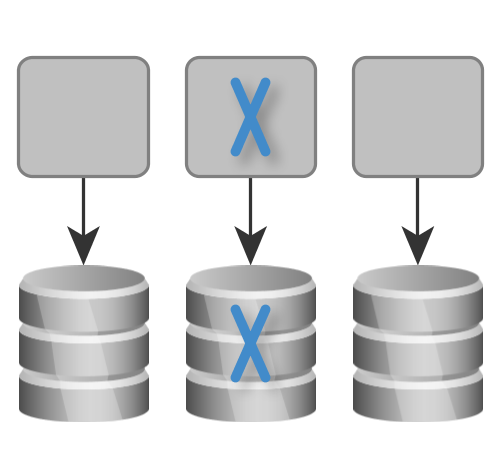
Separated Data Sources: We only have to coordinate the database changes with one application. This makes deployment much easier.
The Rule: Use separated databases or at least separated schemas for each deployment unit. This way, we only have to coordinate changes in the database with one application, which makes deployment much easier. This is a huge benefit when we change and deploy our application frequently, which is what we want to do when it comes to Continuous Delivery.
But this means that we need to slice our system vertically into deployment units. If every deployment unit has its own GUI, business logic and database, we can deploy them independently. The microservice architecture enforces independent deployment units.
Challenges: Schema Update and Data Migration
Let’s assume we want to deploy a new version of our Ordering service, but the new version needs a new column in the Ordering table. Hence, we can’t simply deploy the new version, because it won’t be compatible with the current schema of the production database. There are two things we have to do before we can deploy our new application:
- Schema Update. We need to change the schema of the production database and add the new column.
- Data Migration during Operation. We need to migrate the existing data to the new structure. This is tricky if no downtime is allowed.
Schema Update
Relational Databases
Relational Databases have a fixed schema. If we want to add a column, we need to change the schema and migrate the existing data. Doing this manually is laborious and error-prone – especially, when we release frequently. Therefore, we need an automatic mechanism that updates the schema and migrates the existing data. Examples of such migration tools are Flyway, Liquibase or DbMaintain.
The following image illustrates the principle of these tools:
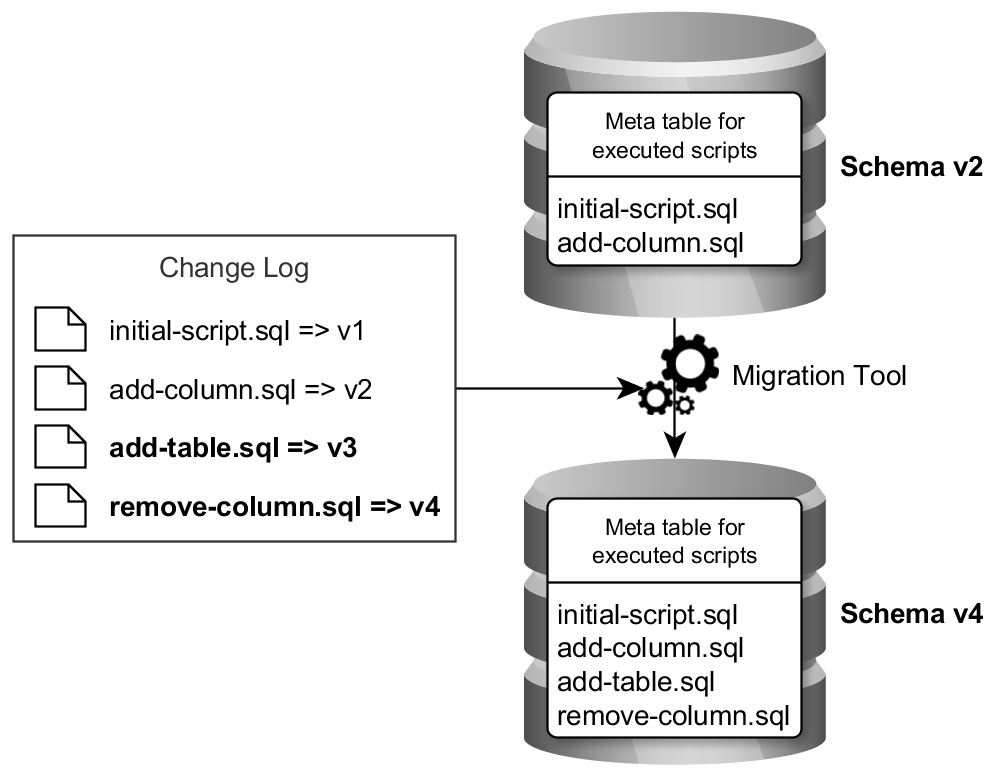
A Migration Tools tracks the schema changes and knows which schema changes have not been performed yet. This way it can automatically update a schema of any version to the most recent version.
The migration tools track the changes performed on the database. It maintains a protocol of the schema changes. This is a meta table in the database that contains all SQL scripts that have been executed on the database. Moreover, there is a change log containing every SQL script. If we want to change the schema, we create a new SQL script and add it to the change log. If we now want to update the schema to the latest version, the tool compares the executed scripts in the meta table with the scripts in the change log, computes the difference (add-column.sql, remove-column.sql in the image above) and executes the missing scripts.
- The migration tools version the schema by tracking the changes. It provides a unified and automatic mechanism for updating a database.
- It can automatically update the database from an arbitrary schema version (or an empty database) to the most recent version.
- We don’t need to distinguish between scripts for development, migration or production anymore. We can run the same automatism.
NoSQL Databases
NoSQL databases typically don’t have a restricting schema. Therefore entries can have arbitrary fields. Consequently, data with old and new structure can exist at the same time. For instance, there can be Ordering entries with or without a new property X. This means, that we aren’t forced to update a schema, because there is no schema at all. So there is no need for a mechanism for schema update, which simplifies the deployment.
Sure, we have to make sure, that our application handles the variable data structure (e.g. the case, that a property may exist or not). We have to code this cases into our application, which may be error-prone. But as long as we ensure this, we can deploy our application and don’t have to care about the database. Hence, using a NoSQL database significantly simplifies the (continuous) delivery. This a huge benefit.
Data Migration during Operation
Updating the production application and database can be a huge challenge. There are two possible scenarios.
Scenario 1: Maintenance Window Possible
We are updating an application without high-availability requirements (like a batch system, backend system, company-internal application). In this case, we can shut down the application for a certain amount of time (the maintenance window, e.g. at night), update the database, deploy the new application and restart. That’s pretty easy.
Scenario 2: No Downtime Allowed
Our business requires high-availability and no downtime (e.g. e-commerce). An offline web shop means lost customers and income, which is not acceptable. In this case the coordination of the deployment and the database update is demanding.
Let’s assume a typical deployment infrastructure for this use case: The Blue/Green Deployment. In this setup there are two application instances running on separate servers. An upstream router enables the update of an instance, without any downtime. However, the instances share the same database.
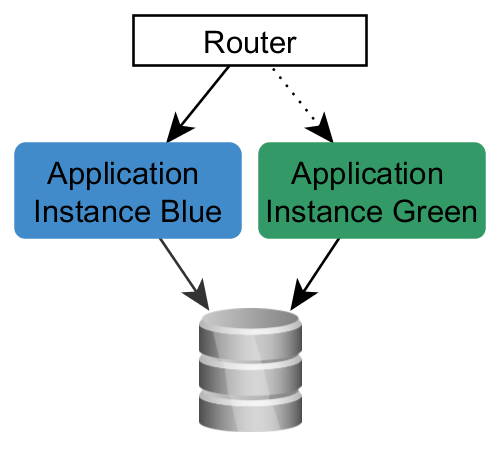
Blue/Green Deployment
The shared database requires a coordinated and gradual approach. We transfer the database state with many small steps to the new state without any downtime. Every change has to be backwards compatible (see above). Let’s assume that we want to remove the column “DisplayName” from the USER table and Blue is currently online.
- DB Change 1: First, we have to make the column optional in the database.
- App Change 1: We update Green with an application version, that doesn’t write and read the column anymore.
- Router Change 1: Green goes online. Blue is offline.
- DB Change 2: Now we can safely remove the column from the database, because it’s not used by Green.
As we see, there is a coordinated approach necessary. However, this is still an easy use case, because we only deploy the application once. It’s getting tricky, if we want to rename a column from “Name” to “Username”. We can’t just rename the column, because our application is accessing it.
- DB Change 1: We add an empty column “Username”.
- App Change 1: We update Green with an application version that writes both columns “Name” and “Username”. But it still reads the old column “Name”.
- Router Change 1: Green goes online. From now on “Name” and “Username” are written.
- DB Change 2: Transfer all database values from “Name” to “Username”.
- App Change 2: We update Blue with an application version that reads and writes only the new column “Username”.
- Router Change 2: Blue goes online. From now on, only the new column “Username” is used.
- DB Change 2: We remove the old column “Name” from the database.
This gradual approach is demanding and very laborious, since we have to schedule every change and deploy intermediate versions of our application. That’s why it’s a pragmatic alternative to collect database changes and execute them in well scheduled downtime of our application. However, this contradicts our no-downtime-requirement and the idea of Continuous Delivery.
NoSQL Databases
Although there is no schema in NoSQL databases, data migration is also an important topic. Let’s consider two cases:
- Simple change (for instance changing the type of the column “TelephoneNumber” from int to string): Migrating the existing entries is not required as long as our application handles the possible different types. Although we don’t need to migrate our data, we may still want to in order to keep our data model consistent. Hence, we may also need to apply the gradual approach described above.
- Complex change (rearrange data structure, like change nesting, migrate data from one collection to another, split or merge collections). This change may be necessary to query data. This is a where a drawback of NoSQL databases gets critical: the query inflexibility. We need to structure the data according to our query requirements. As the requirements changes, we need to query data differently, which requires a different data structure. Hence, we have to do the laborious data migration more often than with relational databases. In relational databases we can get out every data we want (via joins) as long as the data model is normalized (query flexibility).
As we see, using NoSQL databases can help us a lot to simplify the delivery and deployment process (no schema update necessary). But they can force us to update the data model more frequently which is laborious when there is no downtime allowed.
References
- Eberhard Wolff: “Continuous Delivery” (German)
- Thorsten Maier: “Continuous Delivery und die Datenbank. Unterschätzte Herausforderungen” (German). JavaMagazin 11 2015.