Microservices in a Nutshell. Pros and Cons.
Posted on Apr 11, 2015. Updated on Dec 10, 2019
Microservices are an interesting approach for achieving modularization of an application. An application is built as a set of services. These services can be independently developed, tested, built, deployed and scaled. However, microservices are not suitable for every use case. This post discusses the benefits and drawbacks of microservices.
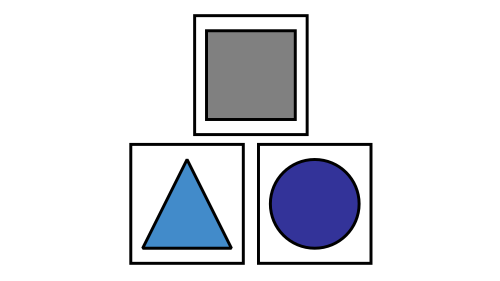
Microservice Architecture
Microservices are a modularization approach. Applying microservices means to compose an application out of independent services running in separate processes. Therefore microservices can be independently deployed. Within a service you can use any technology and infrastructure. The services typically expose their functionality through a REST API and exchange HTTP messages to interact. Contrarily, in a monolith all components run in the same process and infrastructure (typically an application server), are poorly isolated and interact with each other via in-process methods calls.
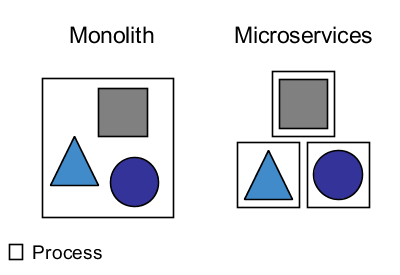
Monolith vs Microservices
When it comes to scalability, microservices can demonstrate their benefits. If we want to scale a monolith we have to scale all components even if there is only one component that is the bottleneck. We waste resources and increase complexity. But scaling microservices is easy. Since all services are independent applications we can only scale certain services while leaving the other services untouched.
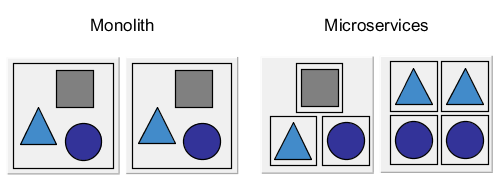
Scaling Microservices
For taking advantage out of microservices, it is important that each microservices have their own data source. Otherwise the services are not completely independent anymore.
Moreover, it’s critical how to slice up an application into services. This should be done domain driven. For instance, we can create a service for user management, billing and ordering. As a criteria consider the following question: Which parts of the application do you want to update or replace independently?
Pros
Benefits in General
You gain real independence and modularization.
- Independent, easy and frequent deployment. One service can be tested, built and deployed without doing this for all services (or the whole application).
- The deployment unit is smaller. This simplifies and speeds up the build and release workflow. In turn, you can deploy more frequently. Due to the increased build speed you get feedback faster from the continuous integration server after a commit of code changes.
- Moreover, the release of one service is not blocked by unfinished work in another service. Besides, the risk of a deployment becomes less, because we only deploy a small part of the system and not the whole one.
- All in all, Continuous Delivery can be applied easier.
- Independent scalability. Fine-grained scaling. We can scale the services that are bottlenecks while leaving the uncritical services untouched.
- High testability due to the independence of the services and a well-defined contract between them (a few coarse-grained REST calls are easier to test than a lot of fine-grained in-process-calls).
- Independent technology stacks can be used (e.g. graph-based, relational, document-based or key-value-based databases; architecture within a service). Moreover, you only include the infrastructure you need. Besides, no long-term commitment to a technology stack is required. This enables modular, polygolt and multi-framework applications.
- Independence in case of failure. Defective services don’t crash the whole application (as long as you implement your services with resilience in mind).
- Independent and parallel development. Team A can develop (and deploy) service A independent from Team B. There is less communication and dependencies and business features can be developed faster. This is an important point if you try to convince your manager of microservices.
Benefits when Going Without an Application Server
Does the microservices approach mean I have to setup, configure and run one application server for each service? What a configuration nightmare. Fortunately, there are lightweight tools like Dropwizard, Vert.x or Spring Boot. Dropwizard enables you to easily develop and deploy RESTful services. However, to be fair, you can’t compare the huge set of enterprise functionality provided by an application server with a Dropwizard application. Building RESTful services is just one thing you can do with an application server. But let’s assume you want to build a RESTful service (and if you want to build microservices this is not a bad idea).
By getting rid of the application server and using an embedded server instead we benefit from an easy automation, faster deployment and less maintenance effort.

Microservices already contain all infrastructure necessary (like a web server or libraries). Only the JRE and some environment variables have to be provided.
Let’s get more concrete:
- Faster development cycles. You start a Dropwizard application by running the
main()method. This is very fast and can be done without any plugin in your IDE. This is a huge improvement compared to the long turn-around-time when dealing with application server (package application to WAR, start application server, deploy/unpackage WAR in application server). - Easy installation, configuration and deployment. This can be a pain when using application servers.
- Besides, there is no trouble with the hated classpath issues anymore. This whole category of annoying problems simply doesn’t exist any longer.
- Easy to maintain a consistent environment in the several stages of the build pipeline (e.g. development, test system, acceptance system, production system).
- Less effort is necessary to set up the required infrastructure to run the microservice (no installation and configuration of an application server). Therefore, we can apply Continuous Delivery more easily, because it’s simple to create the infrastructure for every stage of the Continuous Delivery pipeline and to deploy the application (just copy and run the fat Jar). By the way Docker goes even a step further and makes Continuous Delivery even more straight-forward.
- Independent update of the provided APIs. If you, for instance, want to update JAX-RS you have to update the whole application server (in every stage of the build pipeline), which it sometimes not easy at all. You absolutely cannot be sure, that your application will run flawlessly on a new version of the application server. Dropwizard and Spring Boot gives you full control over the libraries you are using, because you are bundling them with your application (and don’t hope they are somehow provided by the application server)
- Isolation (regarding to resources). The services don’t need to share CPU, memory and the filesystem. They are separated processes and the operation system manages their resources. In case of an application server, the components share the same resources.
- Unnecessary APIs. Often you don’t need all features provided by the application server. Although today’s application servers have smart lazy-loading mechanisms, you don’t want these libraries to be part of your application (server) in order to be as lightweight as possible.
- Adding libraries one way or another. Often the APIs of an application server is not enough and you have to add certain libraries to your application or the application server. If you have to package libraries either way, why you don’t package all libraries you need? Is there really a need for an application server? Moreover, this would make your application more independent from the infrastructure.
Cons and Challenges
Basically, we have to deal with the problems of a distributed system.
- Increased effort for operations, deployment and monitoring. Each service is a separate deployment units, which has to be released, tested and monitored. This means a) that the delivery workflow has be automated (in order to stay efficient) and b) that there is additional infrastructure necessary (e.g. for ELK-Stack for distributed logging, Graphite and Grafana for metrics, service discovery)
- For achieving independence, a team has to be enabled to cover the whole lifecycle of a microservice (technical decisions, conception, implementation, database, build, operations, monitoring, on standby). This requires organizational changes. Especially competences and power have to move from the architects and managers to the teams.
- Increased configuration management. For each microservice we need to create a dedicated build and delivery pipeline. This includes a Maven build configuration, a Git project, a Jenkins job, a setup for tests, a release mechanism and a deployment approach.
- Unsafe distributed communication. Microservices run in a separated processes and communicate over the network and a dedicated mechanism (like REST calls or messaging). Hence, it’s more likely that something will go wrong (microservice not available, HTTP request or response gets lost) – especially in comparison to a programmatically API call. We have to deal with this and implement approaches to handle those situations (data redundancy and periodical synchronization, timeouts, lost request, lost response, re-try, circuit breaker, fallback strategies, messaging vs REST). We have to make our microservice “resilient”.
- Performance hit due to HTTP, (de)serialization (and network) overhead. Instead of programmatic API calls (in-process) you have to make HTTP calls (over the wire). This can get even more problematic if your requests result in multiple subsequent requests to other services. However, there are approaches that can be applied to reduce cascading requests and improve the response times (data redundancy in a service-own database and data synchronization via messaging or feed polling).
- Transaction safety.
- It’s difficult to maintain transaction safety when dealing with independent processes.
- Besides it’s already tricky to implement transactions correctly within a single microservice, when another microservice should be called after a certain action. What happens if the transaction rolls back, but we already notified a downstream microservice? We have to be more careful with transactions and their scopes.
- Complex testing. In a monolith, all logic lives in one project, which can be easily tested in integration. With microservices, end-to-end testing is usually more challenging as testing all microservices together requires a more sophisticed setup and testing approach as there are more moving parts, data sources and communication involved. But the service cut is important here: Heavily distributed workflows are very hard to test, while leaving workflows within a single microservice improves the testability as end-to-end-tests turn into component tests.
- Service discovery necessary (in case of REST as the communication mechanism). We have to come up with a service registry that allows our microservices to find each other (Netflix Eureka, Consul).
- Less comfortable API. Making HTTP requests (via a client API) and process it (via JAX-RS) is more laborious than doing a comfortable programmatic method call. Moreover, due to the expensive calls you want to reduce the number of calls. Hence, the calls have to be more coarse-grained, which make them more uncomfortable to use.
- Refactorings can be hard. Especially when moving code between services, you have to change all dependent services. The modularization done with microservices is more fix and harder to change.
- Keeping dependent services compatible when updating a single service is tricky. Updating a service should not break all of its consumers. Versioning can solve this problem, but implies other problems (e.g. version conflicts). An alternative is to design a service to be tolerant to changes in their dependent services. Or to still support the old service interface until all consuming services migrated to the new interface.
Further Readings
- I highly recommend the book Microservices: Flexible Software Architecture
by Eberhard Wolff.
- Eberhard Wolff: Java Application Servers Are Dead. Talk (in German). Slides (in English).
- Eberhard Wolff: Micro Services – weder Micro noch Service?. (in German).
- Dave Kerr: The Death of Microservice Madness in 2018. A critical reflection about microservices. Highly recommended.
- James Lewis, Martin Fowler: Microservices.
- David Parnas: On the Criteria To Be Used in Decomposing Systems into Modules (1972). This paper describes the three benefits of modularity. Although the paper is very old, it is still valid.