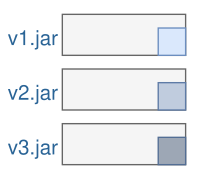
Putting a fat jar into a Docker container is a waste of storage, bandwidth and time. Fortunately, we can leverage Docker’s image layering and registry caching to create incremental builds and very small artifacts. For instance, we could reduce the effective size of new artifacts from 75 MB to only one MB! And the best is that there is a plugin for Maven and Gradle handling everything for us.

I just wanted to convert SVG to PNG files with Python and the library CairoSVG. That was no problem on my Ubuntu system. But running the SVG converter script within a lightweight Alpine Docker container turned out to be problematic. Figuring out which libraries have to be installed up front took me some time. That’s why I like to share my findings here. Hopefully, it’ll save your time.
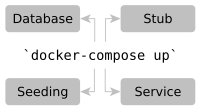
Imagine you clone a git repo and try to start its application in your IDE. It fails. Why? The database is missing. After installing and starting a database manually you look at an empty application. There is no data in the database. Moreover, the application still doesn’t work as it requires an external service… The process of setting up a local development environment is often a journey of pain with many manual actions and implicit knowledge. How cool would it be, if we just have to call docker-compose up and the whole environment is automatically created locally containing nice dummy data?

At a first glance, in-memory databases (like H2 or Fongo) look like a good idea. You can test your code without having to worry about installing and managing a dedicated database server up front. Just start your tests and the H2 database will be up and running. However, this comfort comes with severe drawbacks. In this post, I explain my reservations and point out Docker as an alternative which can be easily used with TestContainers or within the Gradle/Maven build.
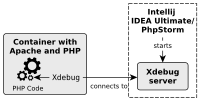
Running PHP and an Apache in a Docker container is very handy for local development. But how can we debug the PHP code running in the container? In this post, I show you how to configure Xdebug in a PHP container and configure IntelliJ IDEA Ultimate or PhpStorm for remote debugging.
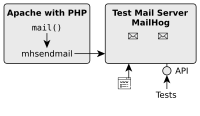
For a small PHP project, I created a Docker container with an Apache and PHP in order to ease local development and setup. But that was not enough because my PHP application also sends mails and I wanted to test this feature locally as well. That’s why I needed a local SMTP server for testing and integrate it into my current Docker composition. In this brief post, I show you how I achieved this.
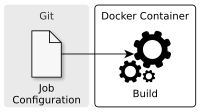
A typical Jenkins 1.0 setup for Continuous Integration (CI) comes with some drawbacks. The job configuration is stored somewhere else but not in the version control system. This makes it hard to set up a new job correctly or to track configuration changes. Another pain point are the various tools (JDK, Maven, node, gulp etc.) that have to be installed and maintained on all Jenkins nodes. This increases the maintenance effort and can slow down the development. Let’s consider some solutions for these issues.
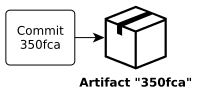
Dealing with version numbers is an important challenge on the way to Continuous Delivery. The classical versioning approach (“8.2.0”) and release workflow is inappropriate, because it can’t be automated properly. This post shows how we can leverage the Git commit hash to get rid of manual workflows and automate the Continuous Delivery pipeline. At the end, every build will produce an artifact which is potentially shippable. We’ll implement this solution with Maven and Docker.
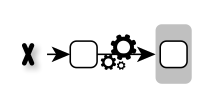
Introducing Continuous Delivery means to automate the delivery process and to release our application frequently. This way, we improve the reliability of the release process, reduce the risk and get feedback faster. However, setting up a Continuous Delivery pipeline can be difficult in the beginning. In this step by step tutorial I will show you how to configure a simple Continuous Delivery pipeline using Git, Docker, Maven and Jenkins.
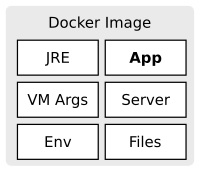
Docker allows us to easily create reproducible environments for our application. We automate the setup of the environment and eliminate manual error-prone tasks. This way we reduce the risks and the reliability of the deployment process. But there are also challenges and domains, where the usage of Docker can be difficult. This post discusses several advantages of Docker and points out some drawbacks.

Dropwizard produces a fat jar containing every dependency your microservice needs to run. This includes a web server. This way, no web server needs to be installed and configured on the target machine. However, there is some infrastructure left (like the JRE) which still has to be installed before the deployment. That’s where Docker enters the stage. With Docker we can produce an artifact containing really everything we need to run our microservice. In this post, we take a look at how we can integrate Docker into our Maven build, run our tests against the container and push the image to a repository.