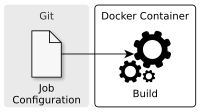
A typical Jenkins 1.0 setup for Continuous Integration (CI) comes with some drawbacks. The job configuration is stored somewhere else but not in the version control system. This makes it hard to set up a new job correctly or to track configuration changes. Another pain point are the various tools (JDK, Maven, node, gulp etc.) that have to be installed and maintained on all Jenkins nodes. This increases the maintenance effort and can slow down the development. Let’s consider some solutions for these issues.
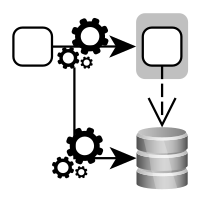
Applying Continuous Delivery means to automate the delivery pipeline and to release frequently. However, databases are a big challenge, because with every deployment we may need to update and migrate our database before we can deploy our application. This post points out solutions for dealing with databases in a Continuous Delivery scenario.
Introducing Continuous Delivery means to automate the delivery process and to release our application frequently. This way, we improve the reliability of the release process, reduce the risk and get feedback faster. However, setting up a Continuous Delivery pipeline can be difficult in the beginning. In this step by step tutorial I will show you how to configure a simple Continuous Delivery pipeline using Git, Docker, Maven and Jenkins.
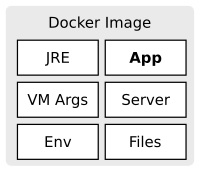
Docker allows us to easily create reproducible environments for our application. We automate the setup of the environment and eliminate manual error-prone tasks. This way we reduce the risks and the reliability of the deployment process. But there are also challenges and domains, where the usage of Docker can be difficult. This post discusses several advantages of Docker and points out some drawbacks.