
Hibernate is my daily business. And it bugs me. Hibernate adds non-trivial complexity to your application and restricts the flexibility in terms of the query capabilities and the class design. Fortunately, there are many alternatives available. In this post, I like to recap some drawbacks of Hibernate and present an alternative: Do-it-yourself ORM with plain SQL, Spring’s JdbcTemplate and compact mapping code powered by Kotlin.

On September 29, 2017, I will give a talk about ‘Kotlin in Practice’ at the JUG Saxony Day in Dresden. In my talk, I will give a short introduction to Kotlin and talk about the experiences we made at Spreadshirt with Kotlin. I’ll show how we can benefit from Kotlin when it comes to popular Java frameworks and if there are pitfalls we have to pay attention to. I’m really looking forward to this conference and I’m happy to be part of it.

At a first glance, in-memory databases (like H2 or Fongo) look like a good idea. You can test your code without having to worry about installing and managing a dedicated database server up front. Just start your tests and the H2 database will be up and running. However, this comfort comes with severe drawbacks. In this post, I explain my reservations and point out Docker as an alternative which can be easily used with TestContainers or within the Gradle/Maven build.
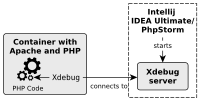
Running PHP and an Apache in a Docker container is very handy for local development. But how can we debug the PHP code running in the container? In this post, I show you how to configure Xdebug in a PHP container and configure IntelliJ IDEA Ultimate or PhpStorm for remote debugging.
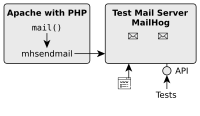
For a small PHP project, I created a Docker container with an Apache and PHP in order to ease local development and setup. But that was not enough because my PHP application also sends mails and I wanted to test this feature locally as well. That’s why I needed a local SMTP server for testing and integrate it into my current Docker composition. In this brief post, I show you how I achieved this.

With Kotlin we can write code that is easy to understand, short, expressive and safe. Sounds like clean code, doesn’t it? In this post, I go through some recommendations and principles of clean code and consider if Kotlin can help to fulfill this rules or not. Moreover, I show restrictions and points, where we should be careful. At the end, I discuss if Kotlin leads to “a dark or a bright path”.

On June 21, 2017, I will give a talk about ‘Cleaner Code with Kotlin’ at the Clean Code Days in Munich. In my talk, I will discuss where Kotlin can help us to write Clean Code and where not. Besides, I will point out how we can get rid of Java’s bloated boilerplate and why we should be careful with some of Kotlin’s features. I’m really looking forward to this conference and I’m happy to be part of it.

In order to take full advantage of Kotlin, we have to revisit some best practices we got used to in Java. Many of them can be replaced with better alternatives that are provided by Kotlin. Let’s see how we can write idiomatic Kotlin code and do things the Kotlin way.
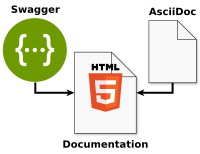
Writing documentation manually for a RESTful API can be laborious. On the other hand, relying exclusively on the generation of the documentation (e.g. with swagger-ui) is often not sufficient. There are always aspects (like common use cases and workflows) that need to be described manually. Let’s see how we can combine these two approaches with the help of AsciiDoc!
