
I’m using MongoDB in production for many years. In this time, I tried different tools and development approaches; some turned out to be useful for us, others don’t. In this post, I like to share handy CLI tools for working with MongoDB, a Docker-based local development approach and helpful Mongo shell snippets.

MongoDB’s dynamic schema is powerful and challenging at the same time. In Java, a common approach is to use an object-document mapper to make the schema explicit in the application layer. Kotlin takes this approach even further by providing additional safety and conciseness. This post shows how the development with MongoDB can benefit from Kotlin and which patterns turned out to be useful in practice. We’ll also cover best practices for coding and schema design.

Hibernate is my daily business. And it bugs me. Hibernate adds non-trivial complexity to your application and restricts the flexibility in terms of the query capabilities and the class design. Fortunately, there are many alternatives available. In this post, I like to recap some drawbacks of Hibernate and present an alternative: Do-it-yourself ORM with plain SQL, Spring’s JdbcTemplate and compact mapping code powered by Kotlin.

At a first glance, in-memory databases (like H2 or Fongo) look like a good idea. You can test your code without having to worry about installing and managing a dedicated database server up front. Just start your tests and the H2 database will be up and running. However, this comfort comes with severe drawbacks. In this post, I explain my reservations and point out Docker as an alternative which can be easily used with TestContainers or within the Gradle/Maven build.

Auto increment IDs are not working well when it comes to distributed databases. Instead, we should use UUIDs. Let’s consider the pros and cons of UUIDs and how we can use them with Hibernate and MySQL.

I attended the course “MongoDB for Java Developer” (M101J). It was fun and I learned a lot about MongoDB. I like to share my gained knowledge and experience in a two-part series. In this first part I assess the course and state, whether or not the course is worth the time.
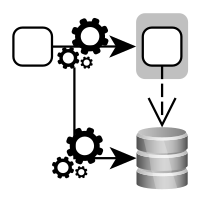
Applying Continuous Delivery means to automate the delivery pipeline and to release frequently. However, databases are a big challenge, because with every deployment we may need to update and migrate our database before we can deploy our application. This post points out solutions for dealing with databases in a Continuous Delivery scenario.
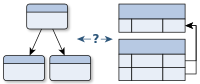
Relational Databases seem to be the universal hammer in the toolbox of every developer. There is the notion that you can solve every problem with it – you just have to smash hard enough. However, if you use relational databases out of habit, you can easily run into troubles when it comes to schema evolution, scalability, performance or certain domains. This post discusses the strength and weaknesses of relational databases and points out alternatives.