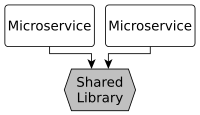
Extracting common code to a library seems to be developer’s best practice. Reuse boosts the development, doesn’t it? However, in a microservice architecture shared libraries tightly couples microservices together. You lose a huge benefit of microservices: independence. In this post I like to point out why shared libraries are not a good idea and present alternatives.

Testing RESTful Web Services can be cumbersome because you have to deal with low-level concerns which can make your tests verbose, hard to read and to maintain. Fortunately, there are libraries and best practices helping you to keep your integration tests concise, clean, decoupled and maintainable. This post covers those best practices.

I attended the course “MongoDB for Java Developer” (M101J). It was fun and I learned a lot about MongoDB. I like to share my gained knowledge and experience in a two-part series. In this first part I assess the course and state, whether or not the course is worth the time.

When we apply Model-Driven Software Development (MDSD) we write a generator which produces code out of a model. The promise is that among others, we can reduce the boilerplate code and accelerate the development. However, MDSD is not a cure-all and should be applied with sound judgment. In this post I cover some drawbacks of the generator approach, anti-patterns and present an alternative to generators: frameworks.

Does your Vaadin application scale well? As Vaadin holds the UI state of every user on the server-side, the used server memory increases with every active user. So can our Vaadin application deal with an increased amount of users in terms of the used memory? We will find out! In this post I present tools and approaches to investigate the memory footprint of our Vaadin application.
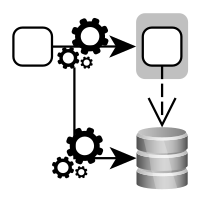
Applying Continuous Delivery means to automate the delivery pipeline and to release frequently. However, databases are a big challenge, because with every deployment we may need to update and migrate our database before we can deploy our application. This post points out solutions for dealing with databases in a Continuous Delivery scenario.
Introducing Continuous Delivery means to automate the delivery process and to release our application frequently. This way, we improve the reliability of the release process, reduce the risk and get feedback faster. However, setting up a Continuous Delivery pipeline can be difficult in the beginning. In this step by step tutorial I will show you how to configure a simple Continuous Delivery pipeline using Git, Docker, Maven and Jenkins.
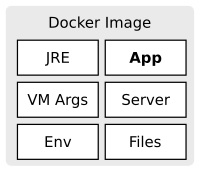
Docker allows us to easily create reproducible environments for our application. We automate the setup of the environment and eliminate manual error-prone tasks. This way we reduce the risks and the reliability of the deployment process. But there are also challenges and domains, where the usage of Docker can be difficult. This post discusses several advantages of Docker and points out some drawbacks.

Dropwizard produces a fat jar containing every dependency your microservice needs to run. This includes a web server. This way, no web server needs to be installed and configured on the target machine. However, there is some infrastructure left (like the JRE) which still has to be installed before the deployment. That’s where Docker enters the stage. With Docker we can produce an artifact containing really everything we need to run our microservice. In this post, we take a look at how we can integrate Docker into our Maven build, run our tests against the container and push the image to a repository.